

Los algoritmos se han convertido en compañeros inseparables e invisibles, que toman decisiones que afectan a todos los ámbitos de nuestra vida. Proporcionan información sobre nuestros gustos, nuestra capacidad de endeudamiento e incluso predicen nuestras tomas de decisiones. También en el ámbito inmobiliario su uso se está extendiendo de forma significativa y adquiere un papel de gran importancia para los principales actores del mercado: socimis, promotoras, entidades financieras, etc…
Aunque en el mercado ya existen algoritmos capaces de predecir el valor de un activo de forma automática, no todas las predicciones arrojan la misma fiabilidad. El grado de éxito se sustenta en dos pilares fundamentales. Por un lado, la calidad y veracidad de la información disponible y por otro, un modelo estadístico en continua evolución y mejora. Del desarrollo de algoritmos mediante métodos estadísticos y matemáticos para la valoración automatizada de inmuebles (AVM en inglés), se ocupa el Machine Learning, cuyo uso y desarrollo comenzó a desarrollarse en los años 80, y su vertiente ‘Deep Learning’.
¿Qué diferencias hay entre Machine Learning y Deep Learning?

Tanto Machine Learning como Deep Learning pueden definirse como dos formas de Inteligencia Artificial que desarrollan sistemas capaces de aprender por sí solos y de imitar ciertas funciones cognitivas humanas, como aprender y resolver problemas o analizar datos e imágenes de manera exhaustiva para obtener conclusiones relevantes en la materia inmobiliaria. La diferencia principal entre ambos conceptos radica en que el método de aprendizaje en Deep Learning es más sofisticado, complejo y autónomo que el de Machine Learning.
Los métodos de valoración de inmuebles han pasado por diferentes fases. Inicialmente, la valoración de una vivienda se llevaba a cabo mediante métodos estadísticos y matemáticos de homogeneización y en la actualidad conviven y se apoyan en otros modelos de predicción de respuesta, como Árboles de decisión, métodos Ensemble (aquí se incluye el Random Forest), Support Vector Machines (SVM), Redes Neuronales, Regresión y Splines de Regresión Adaptativa Multivariante (MARS).
Inteligencia Artificial y mercado inmobiliario
La capacidad de aprender automáticamente es la característica principal que diferencia a los sistemas de inteligencia artificial de otros menos avanzados. En Deep Learning los sistemas van por capas o unidades neuronales. Estas unidades neuronales pueden definirse como sistemas informáticos dotados de microprocesadores con múltiples conexiones entre ellos, como si de una red de neuronas cerebrales se tratase, que intentan operar de forma análoga al cerebro humano. Su trabajo consiste en concebir algoritmos que puedan registrar datos (por ejemplo, ofertas del mercado inmobiliario e información sobre inmuebles que conocemos, como precios o características) y aprender de ellos. A partir de ahí, son capaces de estimar la importancia de cada una de las variables que intervienen en la generación de datos (estableciendo valores máximos y mínimos, cribando datos atípicos), así como extraer conclusiones para establecer predicciones sobre el precio de una vivienda o conjunto de inmuebles.
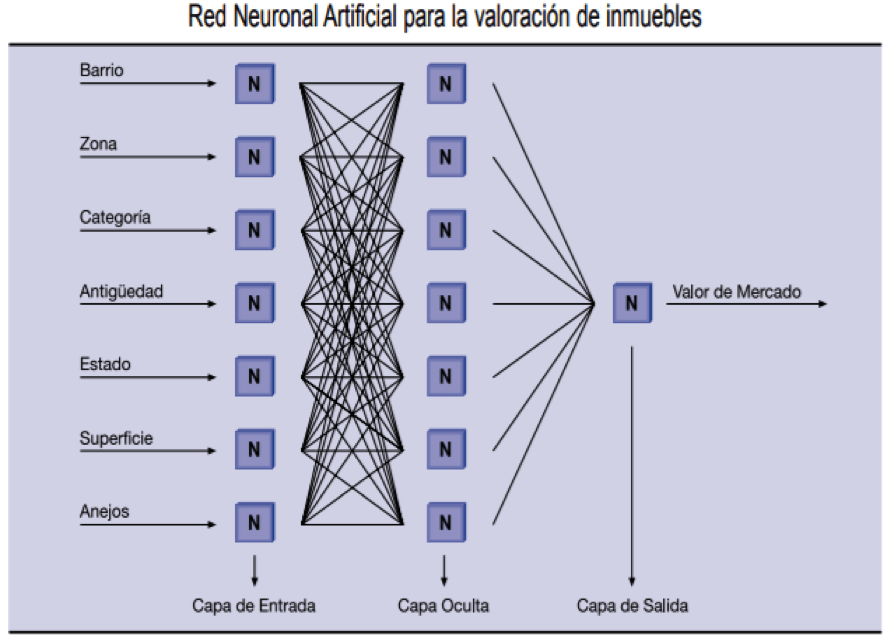
El nivel de evolución actual de la Inteligencia Artificial es asombroso y es fácil pensar que su potencial es ilimitado: ¿Podríamos obtener el valor de una tasación a través de opiniones de los vecinos de un barrio o zona concreta y a través de sus imágenes?
La clave del éxito: la calidad del dato
La tecnología abre un enorme abanico de posibilidades de información vinculado a la explotación del big data. Pero más que la cantidad de datos que se pueda manejar, la clave de un buen sistema es contar con información confiable. Lo que se denomina la “calidad del dato”. En un contexto con infinidad de datos a nuestro alcance, la capacidad de eliminar el “ruido” marca la diferencia. En concreto, para la valoración automática de viviendas, la calidad del dato reside en la rigurosidad, fiabilidad y eficiencia de la base de datos sobre la que se trabaje. Los retos a futuro en este campo residen en la detección de las carencias e incoherencias en todos los datos aportados en un principio y el análisis de sus variaciones y sus mejoras, que serán sometidos al proceso de automatización.
Valoraciones masivas eficientes, prioridad para la banca
El pasado 1 de enero entró en vigor una nueva Circular del Banco de España que, adaptando las normas de contabilidad internacional, obliga a la banca a aplicar un modelo de provisiones más complejo que el anterior. A partir de ahora, el cálculo de provisiones debe basarse en el concepto de pérdida esperada para la cartera, en lugar del de pérdida incurrida. Es decir, se obliga a las entidades a medir el riesgo de todos sus préstamos para anticiparse al mercado y a posibles cambios de ciclo. Además de calcular la posibilidad de impago de los prestatarios, deberán estimar la severidad de la pérdida en caso de que se produzca.
En este contexto, cobra más relevancia que nunca el desarrollo de algoritmos que puedan operar como un cerebro humano y que sean capaces de ofrecer valoraciones con un rigor, fiabilidad y precisión lo más cercano posible al que aporta un tasador que realiza una visita presencial a un inmueble.
La heterogeneidad del mercado inmobiliario hace inviable la existencia de un único método de valoración, pero el disponer de una herramienta tecnológica que efectúe valoraciones de inmuebles de forma ágil y efectiva, que proporcione un cálculo afinado de sus índices de rentabilidad o del valor de una vivienda que se entrega como garantía, supone un avance muy relevante. Sobre todo, por el ahorro de costes y de tiempo que supone a la hora de monitorizar por completo el desarrollo de los mercados inmobiliarios residenciales.
Los retos de futuro de la inteligencia artificial

Las bases están asentadas y los sistemas adaptándose a esta nueva realidad. Los grandes retos para lograr sistemas precisos de inteligencia artificial son:
- Proporcionar a los sistemas estadísticos un volumen de datos suficiente para que los algoritmos puedan reconocer patrones, clasificarlos y categorizarlos con una rigurosidad total.
- Que los propios sistemas estadísticos puedan aprender de los usos que hacen los agentes inmobiliarios para lograr una máxima precisión en sus estimaciones, captando la realidad del mercado inmobiliario a pie de calle a través de modelos de valoración automática centrados en el aprendizaje para optimizar la eficiencia y productividad de los departamentos de tasación y control.
- Que sean capaces de analizar imágenes y fotografías de viviendas para poder detectar la calidad de los materiales y acabados.
El futuro está aquí: la inteligencia artificial ya valora tu casa

Tinsa se encuentra a la vanguardia tecnológica en el ámbito de valoraciones automáticas (AVM) con su herramienta Stima. Se trata de un modelo apoyado en inteligencia artificial que va aprendiendo y depurando la información a partir de los datos procedentes de tasaciones realizadas por técnicos de la compañía.
Ese dato comprobado (la superficie ha sido medida, el estado de conservación visualizado in situ…) es la información de mayor calidad que puede existir y la mejor base a partir de la que construir un sistema inteligente fiable. Y es un elemento distintivo frente a otras herramientas de valoración automática, que utilizan como base información pública procedente de anuncios de oferta u otras bases de datos, que pueden contener inexactitudes.
Stima ofrece a sus usuarios predicciones de precios de un inmueble o grupo de viviendas, de forma comparada dentro de un barrio o de una ciudad. Su método tiene en cuenta un amplio número de factores y propiedades del inmueble (m2, número de habitaciones, año de construcción, si tiene terraza o parking), junto a otros indicadores socioeconómicos (como los relativos a su ubicación). El algoritmo calcula estadísticamente el precio, ofreciendo un resultado en base a la combinación e interrelación de todos estos factores.
El modelo se ha ido depurando hasta el punto de ofrecer un sistema objetivamente preciso, que es capaz de concretar de forma transparente cuán fiable es un resultado en función de la información disponible para su cálculo. El sistema asocia a cada valoración un nivel de confianza de 0 a 7 con un porcentaje de error esperado.
Si quieres conocer más pormenorizadamente cómo funciona Stima, pincha aquí.
Un rigor con reconocimiento europeo
La fiabilidad del modelo de valoración automática de Tinsa está avalado por la European AVM Alliance (EAA), una asociación que agrupa a grandes proveedores de valoraciones automáticas con los más altos estándares de calidad. Tinsa es la única compañía española miembro de este selecto grupo. Fue aceptada en diciembre de 2016, tras una rigurosa auditoría para demostrar y documentar que su modelo de valoraciones automáticas cumple con los exigentes requisitos de transparencia y calidad definidos por la EAA. Esta organización lidera un movimiento paneuropeo para promover y estandarizar el uso de AVM fiables y precisas en Europa, sentando los estándares de cómo los inversores, entidades y reguladores deberían evaluar los resultados de cada método.





